AWS AthenaでParquet形式ファイルを読み込む構成をTerraformで一括で立ち上げた
Amazon Athenaとは?
AthenaはS3内のデータを標準SQLを使用して簡単に分析できるサービスです。
サーバーレスサービスなのでインフラ管理は不要ですが、クエリ実行毎に料金が発生します。
やりたいこと
Athenaの実行に必要なソースとなるS3, やAthenaに必要な各種設定、クエリなどを一括でTerraformで構築したいと思います。
TerraformはAWSやGCPなどのリソースを一括で構築するためのツールです。Terraformの詳しい説明は割愛します。

準備
- AWS CLIのprofile
- Terraform実行環境
ディレクトリ構成
athena_stack/ ├ modules │ ├ athena │ │ ├ sql │ │ │ └create_table_sql.tpl.sql │ │ ├ main.tf │ │ └ variables.tf │ │ │ └ s3 │ ├ main.tf │ ├ outputs.tf │ └ variables.tf └ main.tf
ソースコード
athena_stack/modules/athena
variables.tf
variable "system_name_prefix" { type = string description = "サービスプレフィックス" } variable "s3_database" { type = string description = "Athenaの結果を出力するためのS3バケットid" } variable "s3_source" { type = string description = "ソースとなるデータが保管してあるS3バケットid" }
main.tf
resource "aws_athena_workgroup" "workgroup" { name = replace("${var.system_name_prefix}_workgroup", "_", "-") configuration { publish_cloudwatch_metrics_enabled = false result_configuration { output_location = "s3://${var.s3_database}/results/" encryption_configuration { encryption_option = "SSE_S3" } } } } resource "aws_athena_database" "database" { name = replace("${var.system_name_prefix}_db", "-", "_") bucket = var.s3_database } data "template_file" "create_table_sql" { template = file("${path.module}/sql/create_table_sql.tpl.sql") vars = { athena_database_name = aws_athena_database.database.name athena_table_name = "search_tb" bucket_name = var.s3_source } } resource "aws_athena_named_query" "create_iot_table" { name = "Create ${var.system_name_prefix} table" description = "${var.system_name_prefix}を解析するためのテーブルを作成する" workgroup = aws_athena_workgroup.workgroup.id database = aws_athena_database.database.name query = data.template_file.create_table_sql.rendered }
ここではworkgroup, database, queryの3つを定義しています。 workgroup, databaseまではterraform applyをすれば作成されますが、 aws_athena_named_queryはテンプレートファイルを作成されるだけで、テーブル作成のクエリの実行はAthenaコンソールから手動で実行する必要があります。
sql/create_table_sql.tpl.sql
CREATE EXTERNAL TABLE ${athena_database_name}.${athena_table_name}( `id` int, `lotId` string, `product` string, `timestamp` bigint, `value` int ) PARTITIONED BY ( `year` int, `month` int, `day` int) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1' ) LOCATION 's3://${bucket_name}/raw/' TBLPROPERTIES ( 'projection.enabled'='true', 'projection.day.digits'='2', 'projection.day.interval'='1', 'projection.day.range'='1,31', 'projection.day.type'='integer', 'projection.month.digits'='2', 'projection.month.interval'='1', 'projection.month.range'='1,12', 'projection.month.type'='integer', 'projection.year.digits'='4', 'projection.year.interval'='1', 'projection.year.range'='2020,2100', 'projection.year.type'='integer', 'storage.location.template'='s3://${bucket_name}/raw/year=$${year}/month=$${month}/day=$${day}')
登録するsqlファイルです。 ${}の中にtemplate_fileのvarの値が入ります。 $${year}などは実際に作成されたテンプレートファイルでは${year}のように出力されます。
{ id: 1, lotId: "2022042501", product: "サンプルA", timestamp: 1637291141259, value: 10 }
のようなデータをparquet形式で保存したファイルを読み取れる設定にしています。
parquet形式ファイルの作り方は こちら を参考にしてください。
PARTITIONEDの部分でyear, month, dayを設定するとクエリでyear, month, dayを指定することで検索効率があがります。指定しないと一度全ファイルをスキャンしてデータを表示することになるのでクエリ料金がファイルが増えるごとに増加してしまいます。
今回はPartition Projection(パーティション射影)という設定をしています。この設定により自動で追加データに関してもパーティションの管理をしてくれるようです。
Partition Projectionには、TBLPROPERTIESで以下の設定をする必要があります。 projection.enabled: Partition Projectionの有効化 projection.day.digits: 2に設定することで$${day}のdayが02のように2桁の値を評価できるようになります。$${year}の場合2022なので4と設定しています。 projection.day.interval: 1ずつの間隔のため、1と設定 projection.day.range: とりうる値の範囲、dayの場合は31日までとして、1-31としている projection.day.type: 値の型、数値としたいのでintegerとしている storage.location.template: 読み取るS3データのprefixの形を指定、$${}でprefixから該当する値を取得しています
athena_stack/modules/s3
main.tf
resource "aws_s3_bucket" "bucket" { bucket_prefix = var.system_name_prefix } resource "aws_s3_bucket_acl" "bucket_acl" { bucket = aws_s3_bucket.bucket.id acl = "private" } resource "aws_s3_bucket_public_access_block" "access_block" { bucket = aws_s3_bucket.bucket.id block_public_acls = true block_public_policy = true ignore_public_acls = true restrict_public_buckets = true }
outputs.tf
output "id" { description = "bucketのid" value = aws_s3_bucket.bucket.id }
variables.tf
variable "system_name_prefix" { type = string description = "サービスプレフィックス" }
athena_stack/main.tf
provider "aws" { profile = "<設定したprofile名>" region = "ap-northeast-1" } variable "system_name_prefix" { type = string description = "サービスプレフィックス" default = "sample" } module "s3_source" { source = "./modules/s3/" system_name_prefix = "${var.system_name_prefix}-source" } module "s3_database" { source = "./modules/s3/" system_name_prefix = "${var.system_name_prefix}-database" } module "athena_setting" { source = "./modules/athena/" system_name_prefix = "${var.system_name_prefix}-athena" s3_database = module.s3_database.id s3_source = module.s3_source.id }
デプロイ
$ cd athena_stack // 初期化 $ terrafrom init // 差分確認 $ terrafrom plan // デプロイ $ terraform apply
コンソールで確認
applyが成功するとAthenaのコンソールページへ行くとWorkgroupにsample-athena-workgroup、 databaseにsample_athena_dbが登録されます。
また、テーブル作成用のSQLクエリテンプレートが作成されているのでSaved queriesをクリックし、作成されているCreate sample-athena tableを選択します。
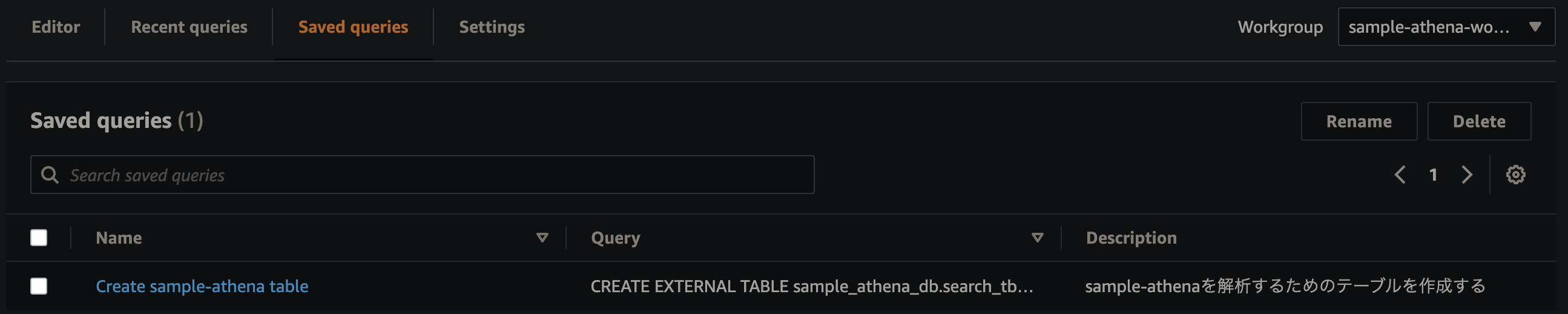
クエリを実行すると、テーブルが作成されます。 ここまで来たら、以下のようなクエリを実行することでデータを検索することができます。
SELECT * FROM "sample_athena_db"."search_tb" WHERE year=2022 AND month=4 AND day=25 limit 10;
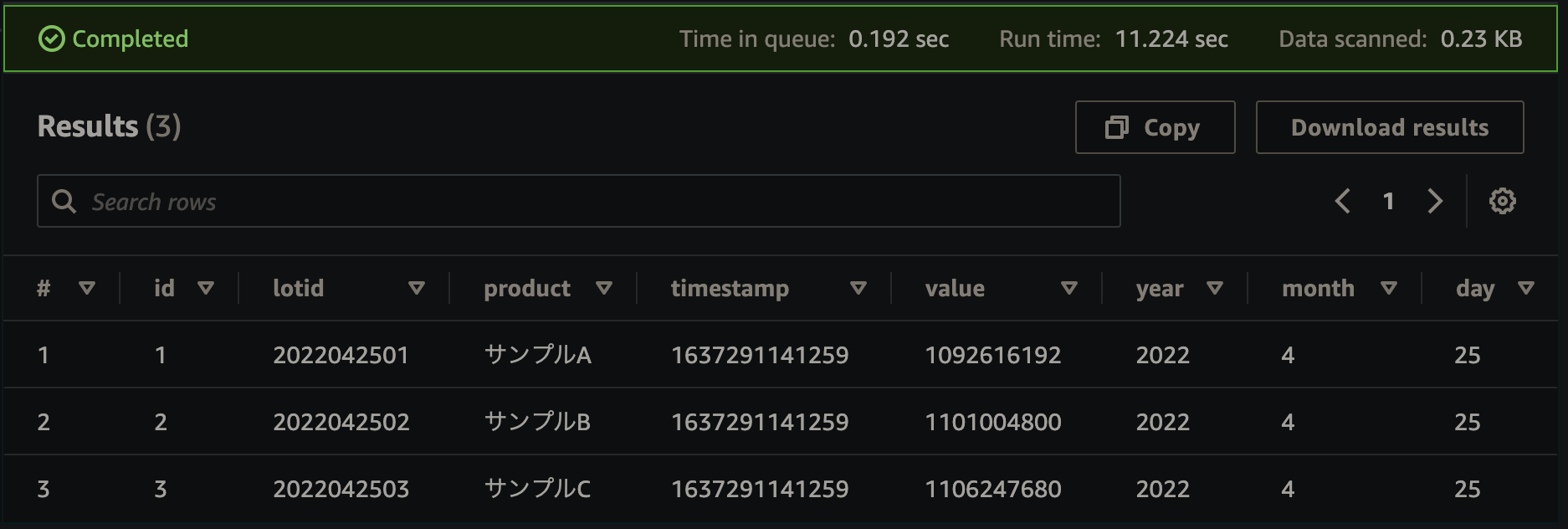
速度検証
S3の中には
WHERE year=2022 AND month=4 AND day=25
に引っかかるレコードを3つだけ入れています。
同じ検索結果でも上記のWHEREを加えるか加えないかで速度がかなり変わりました
WHERE句なし
Time in queue: 0.147 sec Run time: 10.199 sec Data scanned: 0.23 KB
WHERE句あり
Time in queue: 0.171 sec Run time: 0.57 sec Data scanned: 0.23 KB
Data scannedは同じ結果でもRun time時間に大きく差がでるようです。