Node.js(TypeScript)でJsonデータからParquet形式のファイルを生成し、AWS S3へアップロードする
Parquet形式とは?
オープンソースの列指向のデータストレージ形式です。
AWS AthenaなどでS3に上げたファイルにクエリを行う際、CSVファイルに比べると読み込み効率を格段に上げることができ、コストを大幅にさげるなどの活用ができます。
しかし、CSVファイル違いエディタなどで開いた際視認性はないので目視でどんなデータが入っているかなどは確認できません。
詳しくは、
=> https://databricks.com/jp/glossary/what-is-parquet
やりたいこと
Node.jsでJSONデータからParquet形式ファイルを生成し、S3へアップロードする。

セットアップ
実行環境はLambda内を想定
$ yarn add parquets aws-sdk fs-extra @types/fs-extra $ yarn add @types/node ts-node typescript --dev
ディレクトリ構成
lambda/ ├ lib │ ├ ParquetFileCreater.ts │ └ S3Operation.ts └ handler └ index.ts
CDKで以下のようにS3のPutObject権限を付与しました
const lambdaRole = new Role(stack, "LambdaRole", { roleName: "LambdaRole", assumedBy: new ServicePrincipal("lambda.amazonaws.com"), }); lambdaRole.addToPolicy( new PolicyStatement({ resources: putBuckets.map((bucket) => bucket.arnForObjects("*")), actions: ["s3:PutObject"], }) );
ソースコード
</>lambda/lib/ParquetFileCreater.ts
import { ParquetSchema, ParquetWriter } from "parquets"; export class JsonToParquet { static async writeObjects(records: any[], schemaInput: any, filePath: string) { const schema = new ParquetSchema(schemaInput); const writer = await ParquetWriter.openFile(schema, filePath); for (const record of records) { await writer.appendRow(record); } await writer.close(); } }
ParquetSchemaの引数に id: { type: "INT64" } のようなSchema情報を渡す必要があります。
ParquetWriterでSchema情報とfileのパス情報を渡し、writerを生成します。 witer.appendRow()で1recordごとに実行、writer.close()でファイルを生成完了します。
lambda/lib/S3Operation.ts
import * as AWS from "aws-sdk"; // const credentials = new AWS.SharedIniFileCredentials({profile: '<設定したprofile名>'}) // AWS.config.credentials = credentials const defaultS3 = new AWS.S3({ region: 'ap-northeast-1' }) export class S3Operation { static async uploadFile( params: AWS.S3.PutObjectRequest, s3Client = defaultS3 ): Promise<void> { if (!s3Client) { console.log("S3 CLIENT is undefined"); } try { await s3Client.upload(params).promise(); } catch (e) { console.log("データアップロード失敗", e); } } }
AWS SDKのS3クライアントのuploadメゾットを使用します。
params(中身はindex.tsを参照)へBucketNameとkeyを設定、
Bodyにはfs.createReadStream(filePath)のようにReadable Streamを使えます
fs.readFileSync(filePath)はデータ量が大きすぎるとメモリの消費が実行時間がかかってしまうので
createReadStreamのようなReadable Streamで断片的にデータをS3へ送るとメモリ効率よく処理できます
lambda/handler/index.ts
import * as path from "path"; import * as fs from "fs-extra"; import * as os from "os"; import { S3Operation } from "../lib/S3Operation"; import { JsonToParquet } from "../lib/ParquetFileCreater"; const bucketName = process.env.BUCKET_NAME!; export const handler = async () => { const records = [ { id: 1, lotId: "2022042501", product: "サンプルA", timestamp: 1637291141259, value: 10 }, { id: 2, lotId: "2022042502", product: "サンプルB", timestamp: 1637291141259, value: 20 }, { id: 3, lotId: "2022042503", product: "サンプルC", timestamp: 1637291141259, value: 30 } ]; const uploadS3Key = "raw/year=2022/month=04/day=25/2022042501.parquet"; let tmp = ""; try { tmp = fs.mkdtempSync(path.join(os.tmpdir(), "tmpdir")); const tmpFilePath = path.join(tmp, "tmp.parquet"); const schemaInput = { id: { type: "INT64" }, lotId: { type: "UTF8" }, product: { type: "UTF8" }, timestamp: { type: "INT64" }, value: { type: "FLOAT" }, }; await JsonToParquet.writeObjects(records, schemaInput, tmpFilePath); await S3Operation.uploadFile({ Bucket: bucketName, Key: uploadS3Key, Body: fs.createReadStream(tmpFilePath) }); } finally { if (tmp) { fs.removeSync(tmp); } }; }; // handler();
トップレベルのファイルで各モジュールを呼び出し処理を行っています。
fs-extraのmkdtempSync()を用いることで一時ディレクトリを作成し、parquetファイルを一時保存する場所を作っています。
最後にremoveSync()で最後に一時ディレクトリを削除して終了するように構成しました。
結果
処理か問題なく完了すると、
"raw/year=2022/month=04/day=25/2022042501.parquet"
のkeyで指定のS3にparquetファイルが保存されます。
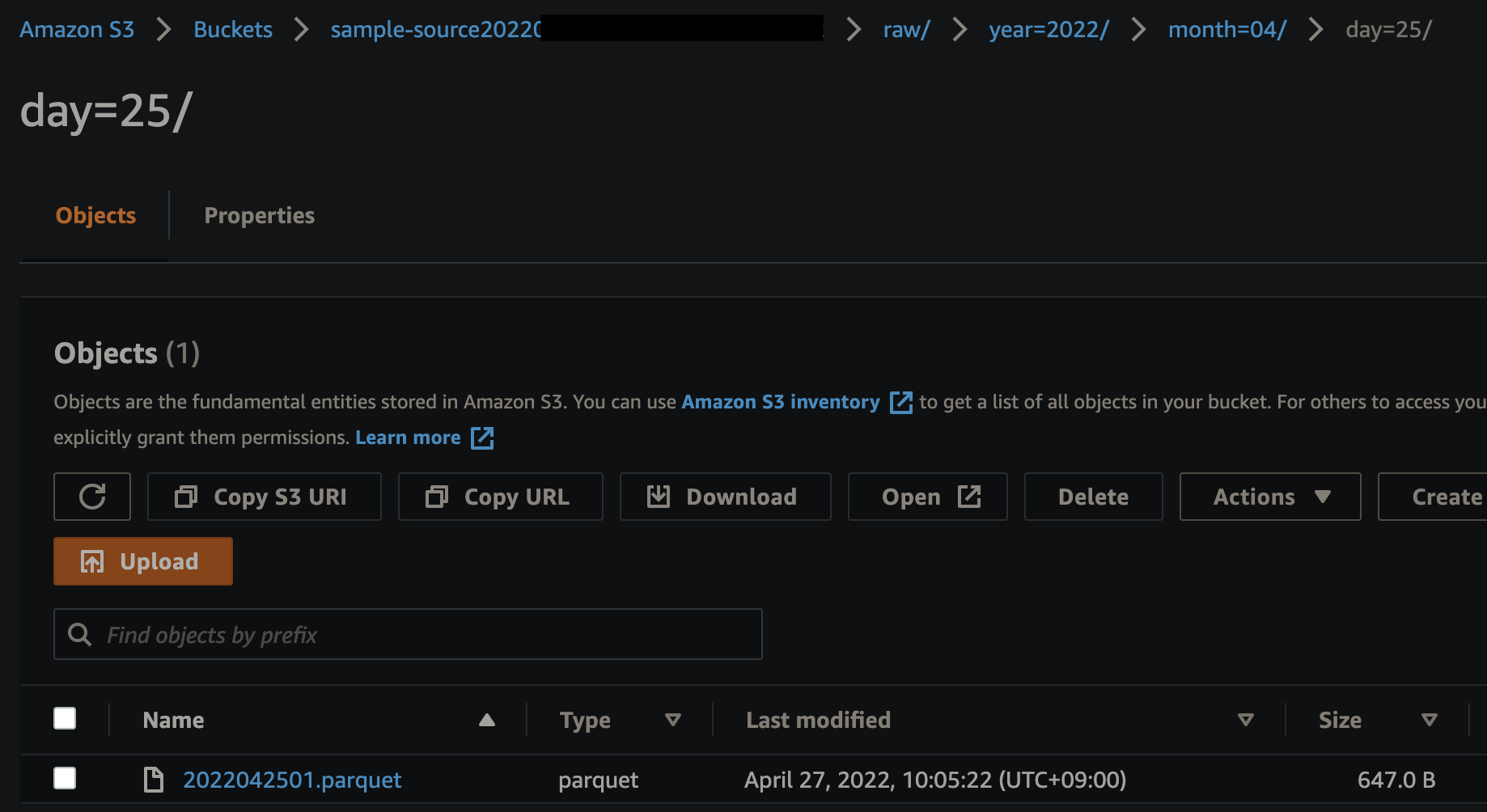
Hive形式
このときあえて,
/{key}={value}/{key}={value}/{key}={value}/
のようなHive形式と呼ばれる形でPrefixを設定しています。
今回は割愛しますがAWS AthenaなどでS3内のファイルへ直接読み込みをかける処理を使用する際、
パーティションを組むのに都合がよくなりますのでS3のPrefixを考える際、Hive形式をなるべく取り入れることをおすすめします。
ローカルで実行(おまけ)
ローカルで実行してS3へアップロードしたい場合、 index.ts
handler();
と S3Operation.ts
const credentials = new AWS.SharedIniFileCredentials({profile: 'eiblog'}) AWS.config.credentials = credentials
のコメントアウトを外して、以下を実行
$ cd lambda $ yarn ts-node handler/index.ts
new AWS.SharedIniFileCredentialsを使用するとローカルで実行したい場合、AWS CLIの権限を持ったprofileを指定することでS3操作権限を持った状態で実行できます。